Week 3: Random Intercept
The Random Intercept Model
Week Learning Objectives
By the end of this module, you will be able to
- Explain the components of a random intercept model
- Interpret intraclass correlations
- Use the design effect to decide whether MLM is needed
- Explain why ignoring clustering (e.g., regression) leads to inflated chances of Type I errors
- Describe how MLM pools information to obtain more stable inferences of groups
Task List
- Review the resources (lecture videos and slides)
- Complete the assigned readings
- Snijders & Bosker ch 3.1–3.4, 4.1–4.5, 4.8
- Attend the Tuesday session to learn about R, and ask questions
- Attend the Thursday session and participate in the class exercise
- Complete Homework 2
Lecture
Slides
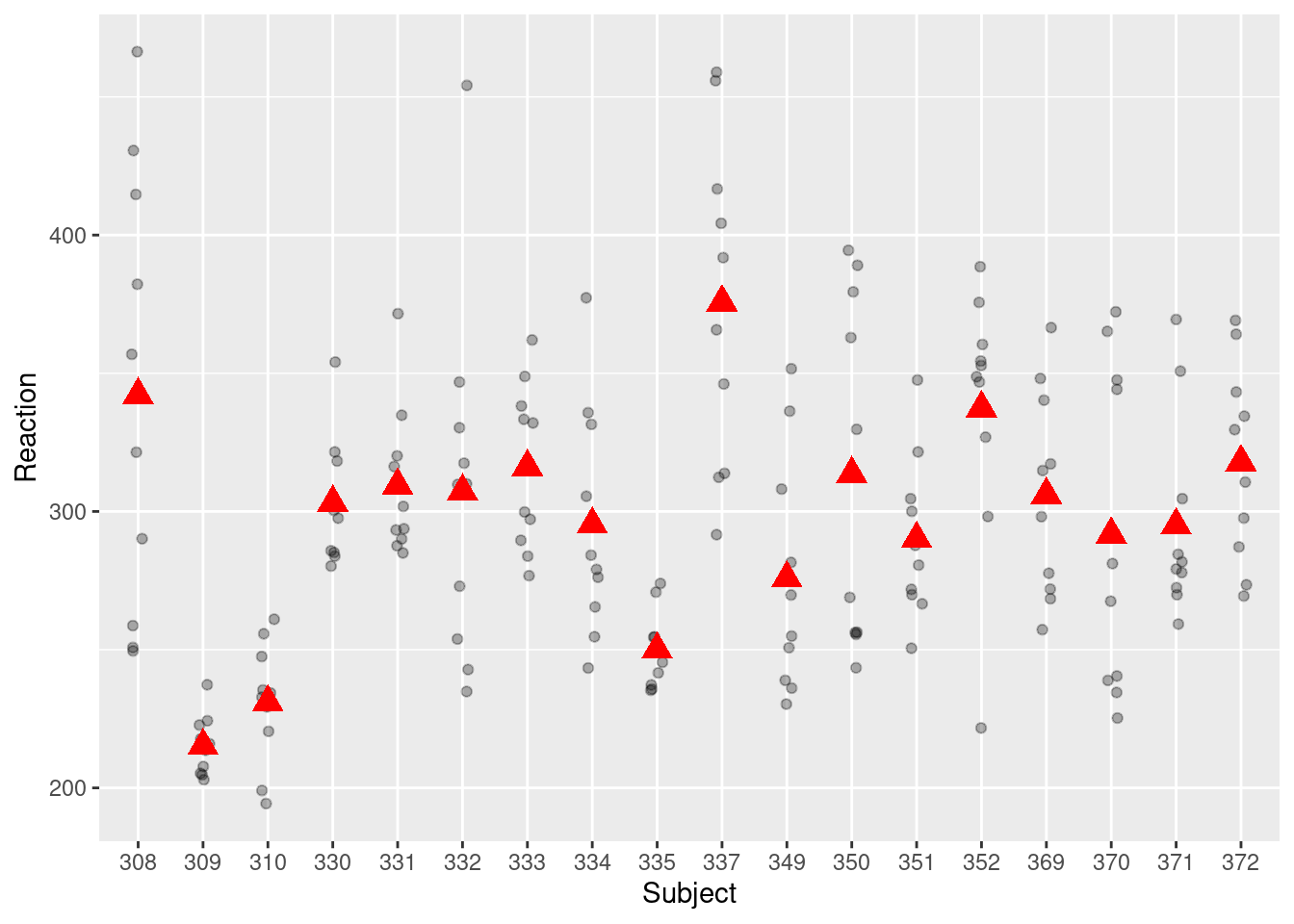
Here’s a snapshot of the sleepstudy data:
where Subject is the cluster ID.
Equations
The graph below shows the distribution of the Reaction variable in the sleepstudy data.
Note: OLS = ordinary least squares, the estimation method commonly used in regular regression.
Note that the ses was standardized in the data set, meaning that ses = 0 is at the sample mean, and ses = 1 means one standard deviation above the mean.
Aggregation
Standard error estimates under OLS and MLM
This part is optional but gives a mathematical explanation of why OLS underestimates the standard error.
If the 95% CI excludes zero, there is evidence that the predictor has a nonzero relation with the outcome.